Gnuxie & Draupnir: early Autumn 2024
Table of Contents
Introduction
Since the last update we've been working mainly on Safe Mode which is really a story about improving the experience for system admins when they encounter an issue with Draupnir. Safe mode aims to cut out the need for a draupnir moderator to defer to their system admin for help in the first place by introducing a concept of recoverable failure modes.
We also made some improvements to what Draupnir logs when it starts to give some feedback to system admins on how Draupnir is configured, for example Draupnir will now log path of the config file and the method being used to load secrets for authentication.
We've had two releases since the last update, beta.7 and beta.8. The first was to collect feedback on safe mode and the second was responding to that, finishing up and releasing safe mode. Go checkout the releases if you haven't already1.
The roadmap has been updated again to plan the final push to v2.0.0, which we expect to release in middle of December.
MSCs and the roadmap going forwards
We've seen a lot more drive-by attacks on public Matrix rooms recently. This hasn't been unexpected, most of 2023 and 2024 felt eerily calm compared to other years, it was inevitable that it would end. The state of safety in the Matrix ecosystem hasn't fundamentally changed in this time, although there had been a reduction in the resources being comitted to safety. On the other hand we have seen the maturing and better organisation of the Community Moderation Effort and their shared policy room. Which has indirectly given communities extra help to handle attacks, to the extent that a it is often the case that other moderators are defending each other's rooms.
I've had ideas for how to make these attacks harder for awhile and they can be split into two catagories. One is proactive moderation, which is encouraging users to participate in the community before they are given the ability to do everything. The other is improving the policies we have for reacting to abuse.
Proactive measures
If you've ever used discourse, then you'll know that it has a really good system here. By default you can't do a lot, and there are goals and milestones you must complete before you are given access to the full set of features, such as the ability to post links and images.
This is really what we need in public matrix rooms, some time to allow new users to interact with the community before we give them to tools to spam our rooms.
Unfortunately Matrix violates the principle of least authority and by default a user or server can send pretty much all of the available message types and links. And any number of messages2. In the worst cases, the only real defense to this is the hope that rate limiting kicks in and that someone sees the attack in time to stop the room being disrupted. In the worst case, these kinds of attacks can destroy a Matrix room and force the room admins to create a new room3. Rate limiting itself is also unreliable and is applied subjectively, even then the behaviour can be complicated by the behaviour of other homeservers that are present in the room4.
For Matrix to be safe we need to apply the principle of least authority at the authorization level, and Matrix also needs to end the irrevocability of the power level system. This is verly unlikely to happen in the next five years. It may never happen if MIMI has made the same mistakes as Matrix and we all end up having to use their protocol.
So we're not going to count on it, We're now going to bring forward a
protection before v2.0.0 is released to help us here and enforce a
custom permission system ontop of the Matrix one. There's a clear need
for it and the state of safety is an unfunny joke.
MSC4204-4207
I have proposed a series of MSCs that help in the reactive case, which
is to help tidy up gore, CSAM, and other abusive content after it has
already been propagated on Matrix. These proposals aim to get us into
a position where we can explicitly mark accounts or content with
m.takedown5 when they post CSAM, gore, or are otherwise just
throwaway accounts used in an attack6.
As currently there is no way to automatically purge media from your homeserver that has been sent to a public room and is known by the room moderators or otherwise to be abusive.
- MSC4204:
m.takedownmoderation policy recommendation - MSC4205: Hashed moderation policy entities
- MSC4206: Moderation policy auditing and context
- MSC4207: Media identifier moderation policy
I don't know when we will implement these MSCs, I had hoped we would get a little bit more feedback first. Implementation will also likely require coordination with other tools. Please do read through the proposals and let me know if you have any thoughts.
Safe mode
Mjolnir and Draupnir don't keep a lot of persistent data around. The number of things that are persisted makes a very short list and they're all stored in Matrix account data. Matrix account data is pretty similar to Matrix state events. The account data has a type, which is sort of just like a string key, and some JSON content to store. Account data isn't limited in size the same way state events are, and only you (and your homeserver) can access your account data.
Draupnir's account data
Protected rooms
The first bit of data that Mjolnir and Draupnir stores in account data
is the list of rooms that they have to protect. When Draupnir
starts, we request this from the homeserver under the type
org.matrix.mjolnir.protected_rooms and we get back a JSON object
with some rooms that we stored earlier. Every time you add or remove
a protected room in either Mjolnir or Draupnir, this account data
gets updated accordingly.
The schema for this account data event isn't documented anywhere, you're technically not supposed to touch it as its internal to Mjolnir. However it is pretty easy to infer a schema from the code.
export const MjolnirProtectedRoomsEvent = Type.Object({ rooms: Type.Array(StringRoomIDSchema), }); export const MJOLNIR_PROTECTED_ROOMS_EVENT_TYPE = 'org.matrix.mjolnir.protected_rooms';
What's unfortunate about this schema is that it stores raw room identifiers, that are supposed to be entirely opaque7. This is ok, but it means means that if all the local users on your homeserver part from the room, the homeserver will no longer know what the room identifier refers to or how to join the room. Now this sounds a little extreme and this wouldn't normally sound like a problem, but unfortunately this does happen quite often for numerous reasons8. Without people realising why.
In order to maintain compatibility with Mjolnir, we can't change this schema without migrating to another format. If we did migrate to another format, we would have to provide downgrade steps if we wanted to maintain backwards compatibility with Mjolnir too.
And then, even if we do have compatibility in both directions, we can still encounter this problem as people upgrade from Mjolnir or older versions of Draupnir.
I want to reiterate again that these are not all strange edge cases
that I've dreamt up, these are all things that have happened to people
who have come to the #draupnir:matrix.org support room for help.
And we've had to send them to Element's /devtools to fix the bot.
Problems with account data are actually the most common support request for us. What's more worrying is the people that don't know how to fix the problem and never make it to the support room. Which is why I saw this as essential to fix. Room moderators using the appservice also have no way of accessing the account data at all. If their Draupnir breaks here, then there is very little that can be done at all even by the system administrator.
Policy rooms (watched lists)
export const MjolnirWatchedPolicyRoomsEvent = Type.Object({ references: Type.Array(PermalinkSchema), }); export const MJOLNIR_WATCHED_POLICY_ROOMS_EVENT_TYPE = 'org.matrix.mjolnir.watched_lists';
Next up, we have mjonlir's watched_lists. This schema is a little
different, this time it stores matrix.to URIs9. These are
actually specified in the matrix spec, and they do provide a way to
join unknown rooms by including via servers encoded as query
parameters in the url itself.
However, there is still a problem. If you used a room alias to watch a list in mjolnir, then chances are this room alias is being stored in the account data of mjolnir without any via servers. What happens is that every time Mjolnir starts, it has to resolve the alias in account data to a room and check that mjolnir is joined to it. Which frequently breaks because the availability of aliases is tied to the single server that provides them. This has been patched for some time, but occasionally this still props up on legacy deployments.
If Mjolnir or Draupnir failed to resolve an alias to a polciy room, they would crash. And this is a good thing, because it stops the server ACL event of all protected rooms being compromised. If the policy room that we can't resolve had lots of server rules, Mjolnir would no longer know about them, and then just emit an ACL event that omitted the old rules.
Enabled protections
export const MjolnirEnabledProtectionsEvent = Type.Object({ enabled: Type.Array(Type.String()), }); export const MjolnirEnabledProtectionsEventType = 'org.matrix.mjolnir.enabled_protections';
The enabled protections don't actually have much that can go wrong. The only data stored here is the name of the protection that is enabled. When Mjolnir loads the list of enabled protections, it tries to find a protection with the same name before enabling it. If Mjolnir doesn't find a matching protection for the name it just warns about it. Still, if different tools are interoperating with this account data, it makes sense that it could become corrupted some other way.
A note on protection settings
Mjolnir intoroduced the idea of protection settings back in 202210. These are basically configuration properties that you can change at runtime via a command. You can even remove and insert items from sets with Mjolnir's protection settings commands. So this is a relatively ambitious and advanced system.
private readonly settings = { maxPer: new NumberProtectionSetting(DEFAULT_MAX_PER_TIMESCALE), timescaleMinutes: new NumberProtectionSetting(DEFAULT_TIMESCALE_MINUTES), }; public async handleEvent(mjolnir, roomId, event) { if (++this.joinBuckets[roomId].numberOfJoins >= this.settings.maxPer.value) { await mjolnir.client.sendStateEvent(roomId, "m.room.join_rules", "", { join_rule: "invite" }); } }
The way these were implemented is by chosing a property name and a parser for each setting that a protection needs. And then these properties get serialized to a JSON object that gets stored as a room state event. This is a pretty similar to pattern to the way Mjolnir stores the data we already discussed in account data. Only this time it's more generic.
This is also pretty close to what we want to use for the account data. There's some structure and understanding about the properties here, ways to mutate them, and we can handle different settings generically.
protection settings in Draupnir
The domain covered by protection settings got moved to the matrix-protection-suite back at the start of the year, and as a part of that there were a couple of changes.
Mainly, mutating any setting for a protection would require the
protection to reload and start again from the fresh state. We decided
to do this to try keep protections a little less stateful. As This
allows for the settings to be destructured and parsed only when the
protection is created. This is what some protections were doing
anyways, they were just bad at it and it caused bugs. By doing this we
also get the bonus of avoiding the convoluted access apis like the one
shown above, specifically this.settings.<property name>.value.
As of writing, protection settings in the Draupnir v2.0.0-beta are
"broken" as a result of the switch to the matrix-protection-suite
and also the changes that were made. Fortunately, as there seems to
be overlap between the persistent configuration Draupnir has,
and the persistent configuration each protection has,
we have an oppertunity to help our future selves who will have to
fix protection settings.
Persistent configuration
So the initial plan for safe mode was to just make something like protection settings work for Draupnir's protected rooms, watched lits, and enabled protections.
Intially I did do this just by copying and adapting protection settings, but there were a couple of issues.
The first issue that I encoutered was that in legacy protection
settings, the description of each setting is mixed up with the
values. So for example, the threshold in BasicFloodingProtection for
the number of events per minute is configurable with an instance of
the class NumberProtectionSetting, which not only describes a
number to provide its serialization and deserialization, but
also wraps the value.
Honestly, I can't remember why I so decisively moved against doing it
this way, but I ended up seperating those concerns. At a guess,
it was because it was complicating type inference or –
aha! It was because it was a pain to integrate with @sinclair/typebox,
which is the library that we use for JSON Schema validation.
I wanted to be able to piggyback off of TypeBox to be able to define
the shape of persistent configs.
export const MjolnirPolicyRoomsDescription = describeConfig({ schema: Type.Object( { references: Type.Array(PermalinkSchema, { default: [], uniqueItems: true, }), }, { title: 'PolicyRoomsConfig' } ), });
So this is what I came up with, we just piggy back off of TypeBox for
everything.
export type ConfigDescription<TConfigSchema extends TObject = TObject> = { readonly schema: TConfigSchema; parseConfig( config: unknown ): Result<EDStatic<TConfigSchema>, ConfigParseError>; properties(): ConfigPropertyDescription[]; getPropertyDescription(key: string): ConfigPropertyDescription; toMirror(): ConfigMirror<TConfigSchema>; getDefaultConfig(): EDStatic<TConfigSchema>; };
There's nothing too interesting here, we have a way to parse the config into the decoded version of the schema type, some introspective methods for describing each property, and a mirror. The mirror is for interacting anything that vaguely matches the config shape, which is important since it works with objects which technically don't pass any validation steps. Since we need to be able to use the mirror to remove invalid values from properties.
export interface ConfigMirror<TConfigSchema extends TObject = TObject> { readonly description: ConfigDescription<TConfigSchema>; setValue( config: EDStatic<TConfigSchema>, key: keyof EDStatic<TConfigSchema>, value: unknown ): Result<EDStatic<TConfigSchema>, ConfigPropertyError>; addItem( config: EDStatic<TConfigSchema>, key: keyof EDStatic<TConfigSchema>, value: unknown ): Result<EDStatic<TConfigSchema>, ConfigPropertyError>; // needed for when additionalProperties is true. removeProperty<TKey extends string>( key: TKey, config: Record<TKey, unknown> ): Record<TKey, unknown>; removeItem<TKey extends string>( config: Record<TKey, unknown[]>, key: TKey, index: number ): Record<TKey, unknown[]>; filterItems<TKey extends string>( config: Record<TKey, unknown[]>, key: TKey, callbackFn: Parameters<Array<unknown>['filter']>[0] ): Record<TKey, unknown[]>; }
It's important to note that the config mirror doesn't mutate the orignal configuration. That's going to be important if we reuse this as a replacement for protection settings later, as we wouldn't want to accidentally mutate a configuration object that's actively being used by a protection.
By the time I had implemented these interfaces, I still thought
that I was going to create some kind editor that could work with
any ConfigDescription and an adaptor for storing them. But
I figured something out that is more convienant and probably just better.
Peristent config data
Just to set some context, now that we have the config description, we also need something that can load and store it from a location.
/** * Allows the client to load persistent config data. * The schema gets verified before its returned. * If there is an error with the data, recovery options are provided. * * Draupnir maintains a list of these which are editable generically * via safe mode. */ export interface PersistentConfigData<T extends TObject = TObject> { readonly description: ConfigDescription<T>; requestConfig(): Promise< Result<EDStatic<T> | undefined, ResultError | ConfigParseError> >; saveConfig(config: EDStatic<T>): Promise<Result<void>>; reportUseError( message: string, options: { path: string; value: unknown; cause: ResultError } ): Promise<Result<never>>; }
This is used to ground a config description against a resource
location, like the org.matrix.mjolnir.watched_lists Matrix account
data.
Config use errors
So far so good, but validation and parsing isn't the only place where configuration values can be the source of an error, or at least involved in an error. Consider the scenario we described where a policy list cannot be resolved when Draupnir starts up. In this situation, the reference to the policy list is valid. So there wouldn't be a problem trying to parse the policy rooms. We only get an error related to a config value when we try to use the policy room reference at run time. So for example if we discover that the server the alias belongs to isn't responding or we've been removed from the room, or some other reason.
To be able to represent those kinds of errors, we basically need
the client code that consumes a config property to report them
in a consistent way. We do this by including a reportUseError
method on PersistentConfigData interface.
Safe mode recovery
It's at this point that I realised that since we're able to report
problems with specific properties, and we have the ConfigMirror that's
able to introspect and manipulate config values. Then it makes sense
that we can just go ahead and suggest a "recovery option" for each
type of error. For example, if we detect that a specific item in
an array doesn't match the JSON Schema, we can just go ahead
and suggest that it can be removed.
Similarly, if we detect there's a problem while using a config value, such as a protected room ID, we can go ahead and suggest that we remove that room from the config.
This is great because we don't have to teach users how to edit or manipulate the config, we can just give them a few options for how to recover their Draupnir, explain them and let them choose.
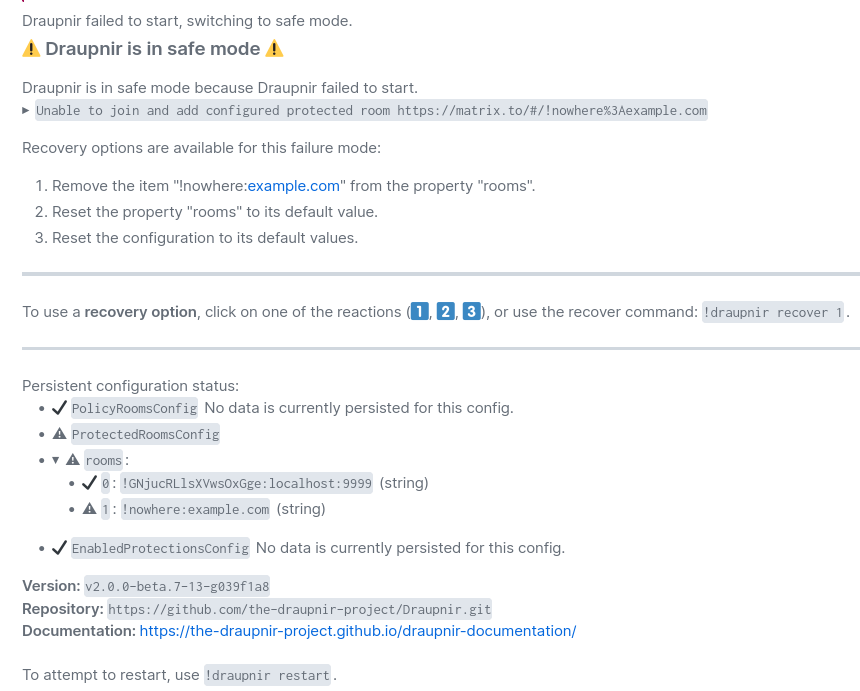
Figure 1: Draupnir starting in safe mode and prompting for recovery
This is how that looks, we try to make it clear which value is causing issues by including the config preview at the bottom.
The warning triangle is supposed to show that this is a config use error, rather than a parsing error. Not that it will make too much difference. Originally these were going to use red, orange, and green buttons but some people can't see the difference between those colors too well idk.
I'm not supper happy with this, but it's important not to lose sight of how big of a change this is over having an unrecoverable bot, and probably not even knowing why.
no-confirm
It became obvious at this point that we should probably include a confirmation prompt in the recover command. So that when you click on the reactions, you get a chance to review everything is ok before continuing.
There are several cases in Draupnir where a confirmation prompt like that would be useful, so I thought it was a good idea to try make the prompt behaviour generic so that it can be used in other commands. We need it in the future too, since I want to be able to do cool things like preview the effects of enabling a protection before confirming.
export const SafeModeRecoverCommand = describeCommand({ summary: "Select an available recovery option to recover Draupnir with.", // .... paremeters keywords: { keywordDescriptions: { "no-confirm": { description: "Do not prompt for confirmation.", isFlag: true, }, }, }, // .... more command stuff });
I don't know whether this was the right choice yet, but I decided that
I would just give special behaviour to the the --no-confirm
option. If you specify the option in the command description, and when
processing the command there is no --no-confirm option, then we will
prompt for confirmation.
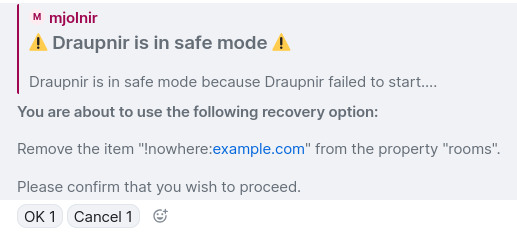
Figure 2: Draupnir safe mode asking for confirmation before using a recovery option
This is what that looks like in the end, this entire message can be changed on a per-command basis with JSX.
For safe mode, I would have liked to have previewed how the config would look after the change but we wouldn't be able able to accurately show config use errors, only parse errors. Because to be able to get those we literally have to try restart draupnir.
Which I guess, yes, we could do that, but that still requires a lot of extra consideration.
Closing
Footnotes:
I've also been experimenting with the CHANGELOG, I'm now trying to follow the https://keepachangelog.com/en/1.1.0/ guidelines but I feel like the reader of the changelog here is other developers because the changelog is for a library, rather than system admins or end users. I don't know what to do about that yet.
Matrix has been designed in knowledge of the possibility of these attacks on Matrix rooms, and concerns have been put aside in the comfort that the attacks are too sophisticated to pull off, or won't happen frequently. They used to happen extremely frequently, without malicious actors needing to run custom homeservers or complicated software, simply because registration requirements in the ecosystem were very relaxed. Safety has been largely neglected. If the protocol is to grow, the reward for conducting attacks will only increase. Attacks will also become easier for malicious parties to carry out as the ecosystem becomes more organised. For example, there has already been a reduction in the bar required to maintain a homeserver.
This happened relatively recently to the Rust Matrix community.
Worse still Matrix technically does not allow power level to be revoked either. Once a user has the ability to send events within one epoch then that is it, they can do that forever. This gets swept under the rug with a mechanic called soft-failure, but these events are still included in the DAG, and will still be propagated under specific circumstances.
This is almost a straight copy of what BlueSky are using for the same purpose. Shoutout to the IFTAS community for creating the space where discussion about some of the harder problems in federated trust and safety can happen.
The reason why we can't just do this at the moment is because we would be classifying accounts or content. Which has legal implications alongside turning your policy lists into something people can use to deliberately find abusive content. With the proposals we're just telling people to take this content down rather than classify it, so if anyone does try to use the list maliciously, they're gonna have to sift through more spam than anything else, hopefully.
To give a couple of examples if you don't buy it, consider single user instances or that the Draupnir is borrowed from another server that doesn't have any local users in the room. Draupnir4all is even deployed this way at the moment. It's quite often that people also kick Draupnir that they were borrowing from their rooms.